Assustador: inteligência artificial do Google pode isolar vozes de pessoas falando ao mesmo tempo em vídeos
Uma nova tecnologia baseada em inteligência artificial permite a Google isolar vozes em arquivos de áudio e vídeo. A novidade foi apresentada no início do mês de abril pela empresa e abre uma série de possibilidades na decodificação de falas em ambientes ruidosos ou com muitas pessoas falando ao mesmo tempo.
A ideia é seguir a mesma lógica que o cérebro humano adota quando estamos tentando prestar atenção na fala de uma pessoa em locais com muito barulho. Mentalmente, é como se deixássemos as demais vozes “no mudo” para poder compreender melhor uma única direção de som. A ferramenta faz algo semelhante.
Louco, não é? Vem com a gente entender melhor isso aí!
®GIPHY
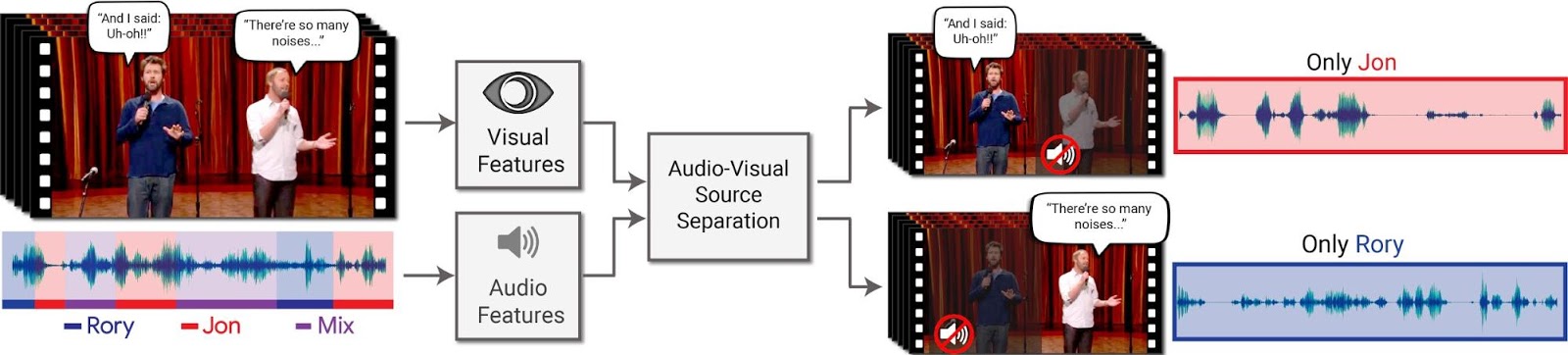
Canais de áudio isolados no mesmo vídeo
Para mostrar o novo recurso, a Google divulgou uma série de vídeos mostrando na prática os resultados. Segundo a empresa, o método empregado funciona com vídeos comuns, coletados na plataforma YouTube, e apresenta resultados muito eficientes.
O algoritmo fica responsável por isolar o sinal de uma voz a partir do momento que o usuário seleciona um dos falantes. Baseado no contexto, ele mantém todos os demais sons ambientes, o que permite ao espectador compreender de forma clara e sem interrupções as falas de qualquer pessoa envolvida em uma conversa, ainda que elas estejam sobrepostas pelas falas de outros.
É importante, entretanto, que os interlocutores estejam visíveis no vídeo. Na demonstração divulgada pela Google, basta ao usuário clicar sobre o falante que deseja ouvir para que o áudio da pessoa em questão seja destacado.
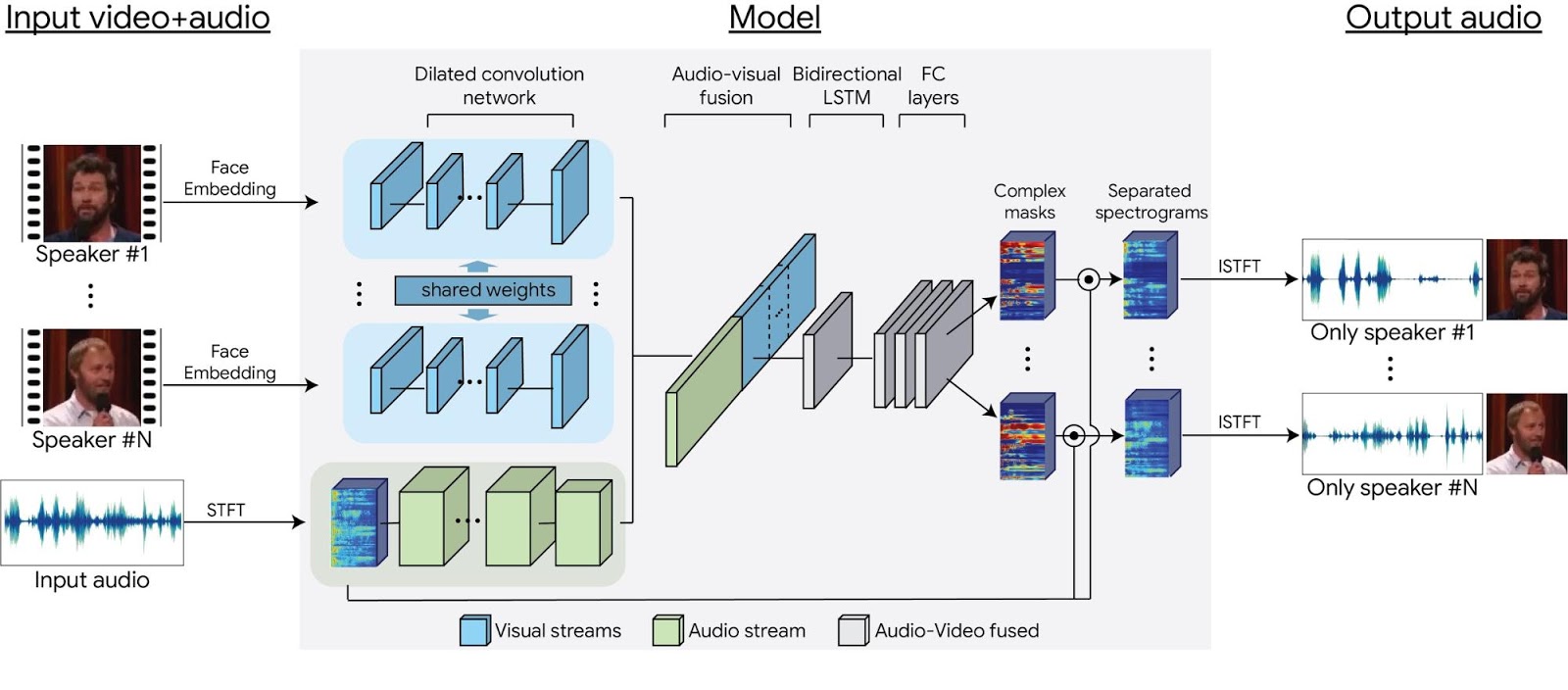
Entendendo o algoritmo
Para tornar possível esse sistema, a Google analisou mais de 100 mil vídeos no YouTube. Depois, foram extraídos áudios de falantes de forma isolada, totalizando mais de 2 mil horas de gravação. Esses dados “limpos” foram então aplicados a outros áudios criando um efeito que a empresa batizou de “synthetic cocktail mixture”.
Esses novos “sons de fundo” serviu de base para que a inteligência artificial do Google pudesse entender como separar essas informações dos timbres dos interlocutores. Depois de todo o processamento, as falas são separadas em canais de áudio distintos, sendo que cada um deles é associado à imagem de um falante.
®GOOGLE RESEARCH BLOG
Para divulgar o projeto, a empresa colocou no ar uma página sobre o assunto, em inglês, com diversos exemplos de bons resultados que a inteligência artificial conseguiu obter. A empresa ressalta que esse é um tema que vem ganhando bastante destaque na comunidade acadêmica, dado o crescente interesse pela análise de discurso.
“Nós vemos uma ampla gama de aplicações para essa tecnologia e estamos constantemente explorando oportunidades de incorporá-la em vários produtos da Google”, destacam Inbar Mosseri e Orang Lang, engenheiros de software da Google em um post no Google Research Blog.
®GOOGLE RESEARCH BLOG
As ferramentas apresentadas pela empresa neste mês ainda têm caráter experimental e não há previsão de quando elas serão incorporadas às plataformas já existentes. Não há nem mesmo confirmação de que isso vá acontecer algum dia e disponibilizada no YouTube, por exemplo.
No entanto, não deixa de ser uma bela demonstração das possibilidades dessa tecnologia num futuro próximo. O que você achou? Conta pra gente!